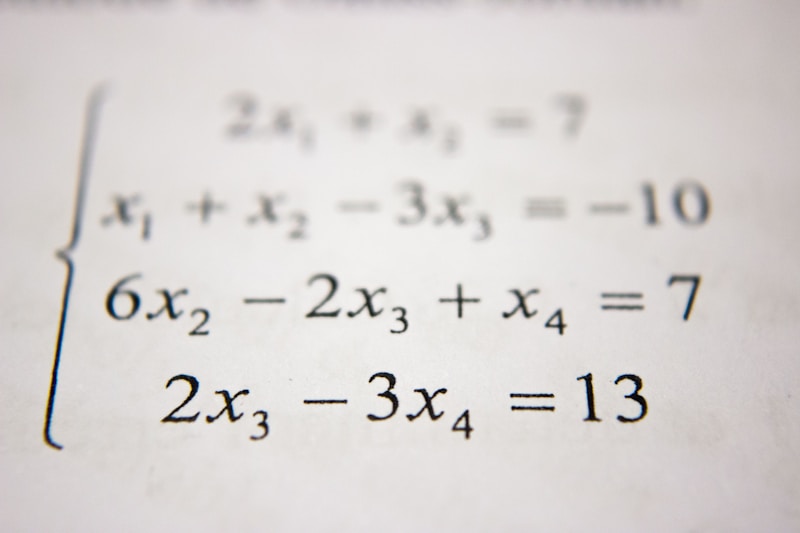📈 正态分布(高斯分布)
概率密度函数
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm
# 正态分布参数
mu = 0 # 均值
sigma = 1 # 标准差
# 生成数据
x = np.linspace(-5, 5, 100)
y = norm.pdf(x, mu, sigma)
# 绑图
plt.figure(figsize=(10, 6))
plt.plot(x, y, 'b-', linewidth=2)
plt.title('正态分布 (μ=0, σ=1)')
plt.xlabel('x')
plt.ylabel('概率密度')
plt.grid(True)
plt.show()
# 随机采样
samples = np.random.normal(mu, sigma, 1000)
💡
AI中的正态分布
神经网络权重初始化、噪声模型、梯度分布等都涉及正态分布。
🔄 贝叶斯定理
核心公式
P(A|B) = P(B|A) × P(A) / P(B)
# 贝叶斯分类器示例
# P(类别|特征) ∝ P(特征|类别) × P(类别)
from sklearn.naive_bayes import GaussianNB
import numpy as np
# 训练数据
X = np.array([[1, 2], [2, 3], [3, 4], [4, 5]])
y = np.array([0, 0, 1, 1])
# 训练朴素贝叶斯分类器
clf = GaussianNB()
clf.fit(X, y)
# 预测
print(clf.predict([[2.5, 3.5]]))
📊 统计量计算
import numpy as np
data = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
# 均值
mean = np.mean(data)
# 中位数
median = np.median(data)
# 标准差
std = np.std(data)
# 方差
var = np.var(data)
# 协方差矩阵(多变量)
X = np.array([[1, 2], [3, 4], [5, 6]])
cov = np.cov(X.T)
# 相关系数
corr = np.corrcoef(X.T)
print(f"均值: {mean}")
print(f"标准差: {std}")