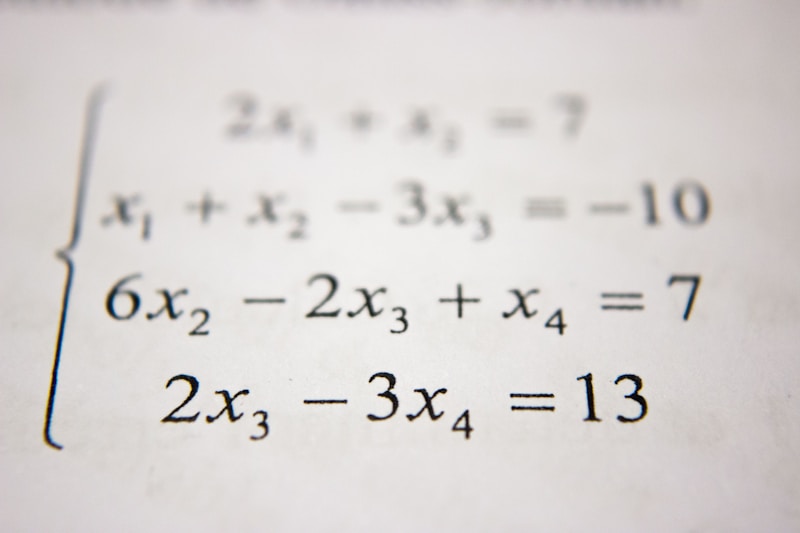💻 代码实现
from sklearn.linear_model import Ridge, Lasso, ElasticNet
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
ridge = Ridge(alpha=1.0)
ridge.fit(X_scaled, y)
lasso = Lasso(alpha=0.1)
lasso.fit(X_scaled, y)
print(f'Lasso非零系数: {(lasso.coef_ != 0).sum()}')
elastic = ElasticNet(alpha=0.1, l1_ratio=0.5)
elastic.fit(X_scaled, y)
🧠 深度学习正则化
import torch.nn as nn
model = nn.Sequential(
nn.Linear(784, 256),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(256, 128),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(128, 10)
)
optimizer = torch.optim.Adam(
model.parameters(),
lr=0.001,
weight_decay=1e-4
)