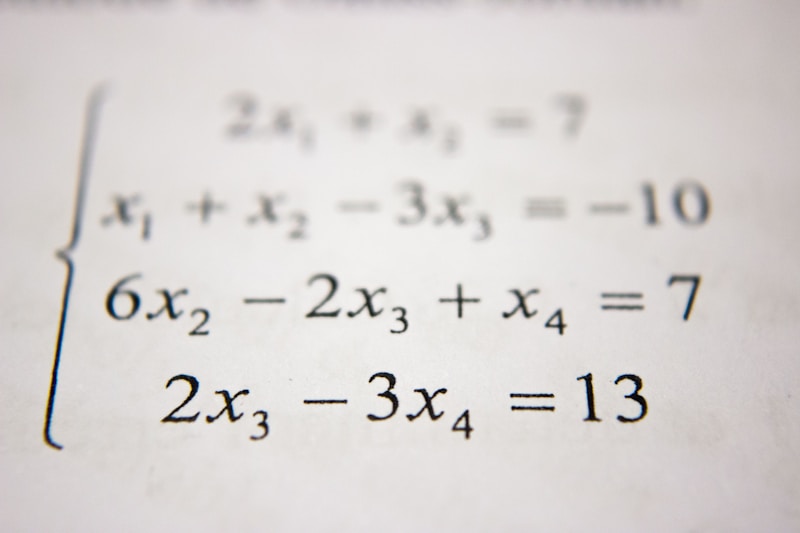💻 使用joblib保存模型
import joblib
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(n_estimators=100)
model.fit(X_train, y_train)
joblib.dump(model, 'model.joblib')
joblib.dump(model, 'model_compressed.joblib', compress=3)
loaded_model = joblib.load('model.joblib')
predictions = loaded_model.predict(X_test)
📦 保存完整Pipeline
from sklearn.pipeline import Pipeline
import joblib
pipeline = Pipeline([
('scaler', StandardScaler()),
('classifier', RandomForestClassifier())
])
pipeline.fit(X_train, y_train)
joblib.dump(pipeline, 'pipeline.joblib')
loaded_pipeline = joblib.load('pipeline.joblib')
predictions = loaded_pipeline.predict(X_new)
📊 模型元数据管理
import json
from datetime import datetime
metadata = {
'model_name': 'random_forest_classifier',
'version': '1.0.0',
'created_at': datetime.now().isoformat(),
'sklearn_version': sklearn.__version__,
'features': feature_names,
'metrics': {
'accuracy': 0.95,
'f1_score': 0.93
},
'parameters': model.get_params()
}
with open('model_metadata.json', 'w') as f:
json.dump(metadata, f, indent=2)